I probably don’t have to tell you what an enormous impact the rise of AI has had on the industry in recent times. It’s amazing to see all the progress that is being made. I knew when I was looking at an upcoming two-day hackathon at iO, I just needed to build something cool with ChatGPT. More particularly, the way you interact with ChatGPT.
Why create a different way to interact with ChatGPT
Personally, I don’t develop AI. I do however interact with it a lot. Like most of you reading, I interact the most with ChatGPT. While the chat interface is great to use while working, It always felt slightly awkward to interact with. When given the choice, I will always rather walk over to someone (or have a call) than use chat to discuss something. It feels a bit more natural as it is the way of communicating that is powered by our natural hardware: speaking and listening. So, if ChatGPT requires me to input text and read outputted text, can’t I just do that by speaking and listening?
I’ve wanted to build a demo application that enables just that. A user can start a conversation with ChatGPT and just talk. Once they’re done talking, ChatGPT processes the text and sends back a response. This response is then read out loud to the user after which the cycle continues.
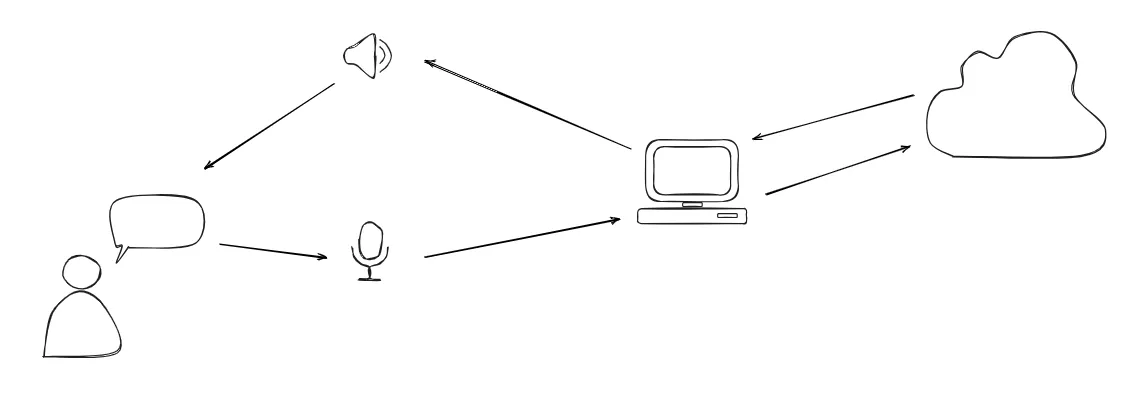 Being a developer for the web, I naturally gravitated to the techniques I would use there. As it turned out in the end, this gave a surprising advantage in the user experience. Here is a quick glimpse of the result called “Aiva”:
Being a developer for the web, I naturally gravitated to the techniques I would use there. As it turned out in the end, this gave a surprising advantage in the user experience. Here is a quick glimpse of the result called “Aiva”:
What techniques to use?
For front-end frameworks, any will do. I’m most comfortable with React.js and Next.js so decided to use those. Also, I always want to try out at least one new thing when creating a demo. This time, that was the component library Radix which focusses on important aspects as accessibility. Also, I can highly recommend using a component library when building demos so building a nice UI doesn’t take away from your time and focus on the thing you are actually trying to build.
Input: SpeechRecognition Web API
For the input, I used the SpeechRecognition Web API. Fun fact, I built an application over six years ago called PresiParrot to automatically create captions when giving a presentation. What I find awesome about using web standards is that even after six years, the application still runs perfectly fine, perhaps even better, as it will always be supported by the browser.
In essence, the SpeechRecognition Web API provides you with a way to use the user’s microphone to capture audio and once they’re done talking, provide you with a text string to use. You can even use interim, or live updated, results if needed.
Why use this?
A big upside for me is the before-mentioned benefit that you get with using a web standard. Another major benefit of using the Web API that is built into the browser is that it’s incredibly quick. This goes for the SpeechRecognition Web API (input) but especially for the SpeechSynthesis Web API (output) which we’ll look at in a bit. Your browser already ships with the logic and voices that you might need, mitigating the need for another service that takes time. This greatly benefits the performance which is always important. But as it turned out, it became a nice surprise while building the demo. Have you ever tried to talk with your Google/Apple/Amazon home device? Whenever you ask something, there is always a few seconds of delay. This takes you out of the illusion that you’re actually having a conversation. As this Web API is so quick and needs no loading time, it feels nearly instant helping to sell the conversation effect.
How to use this?
Using the SpeechRecognition Web API is fairly straightforward. You first see if the Web API is supported in the user’s browser:
if (!('SpeechRecognition' in window || 'webkitSpeechRecognition' in window)) {
// handle fallback
}
Next, as seen in the example above, the Web API can either named SpeechRecognition or webkitSpeechRecognition. We assign it like this and set it up:
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition
const recognition = new SpeechRecognition() recognition.interimResults = true recognition.lang = 'en-US'
We change two settings, first we set interimResults to true so we can receive the interim results while the user is speaking. Next, we set the language the user is going to speak in. Naturally, you can provide UI to alter this, but for the demo english is fine.
With everything configured, our next step is to create an onresult and onend callback:
recognition.onresult = (event) => {
const { transcript } = event.results[0][0]
// do something with transcript
}
recognition.onend = (event) => {
const { transcript } = event.results[0][0]
// do something with transcript
}
I've created this small demo so you can try it out yourself:
Source available on https://codepen.io/davebitter/pen/vYbMxNLNow, for every interim result while the user is talking, you can do something with that transcript string once onresult is called. For instance, you show some live feedback on the screen with what text the Web API interpreted the user’s speech as. Once the user stops talking, the onend is called with the end result. Great! We now have turned speech into a text string to use as input!
Output: SpeechSynthesis Web API
What the SpeechRecognition Web API is for input, the SpeechSynthesis Web API is for output. In it’s simplest form, the Web API allows your computer to read a text string out loud.
Why use this?
As mentioned before, this Web API comes with the browser already built-in! It’s not just the Web API itself, but also a wide range of voices to use. These voices can be from difference countries and even different accents.
How to use this?
Let’s make it read out a text string. First we check whether the user’s browser supports the Web API again and create a constant to use later on. Finally, we need to make a SpeechSynthesisUtterance which is basically a unit of text that the Web API needs to read out loud:
if (!('speechSynthesis' in window && 'SpeechSynthesisUtterance' in window)) {
// handle fallback
}
const synth = window.speechSynthesis
const voices = synth.getVoices()
const preferredVoice = voices.find((voice) => voice.voiceURI === 'Karen')
const utterance = new SpeechSynthesisUtterance('Hello from the computer!')
utterance.rate = 1
utterance.pitch = 1
if (preferredVoice) {
utterance.voice = preferredVoice
}
I've created this small demo so you can try it out yourself:
Source available on https://codepen.io/davebitter/pen/QWYPpaxAs you can see, I can retrieve a list of all the supported voices on the user’s browser. I like the one named "Karen" so decided to store that one if found. Naturally, you can create a dropdown with voices for the user to select the one they like.
Next, we create a SpeechSynthesisUtterance with the text string to read out loud. We can then tweak the utterance a bit more by changing the rate (or speed) and the pitch of the voice. Finally, if our preferred voice is available, we assign it to the utterance as the voice to use.
Now all that is left is to speak:
utterance.onend = () => {
// do something once all the text has been spoken
}
window.speechSynthesis.speak(utterance)
That’s it! We now have both input and output covered.
Tying the two together
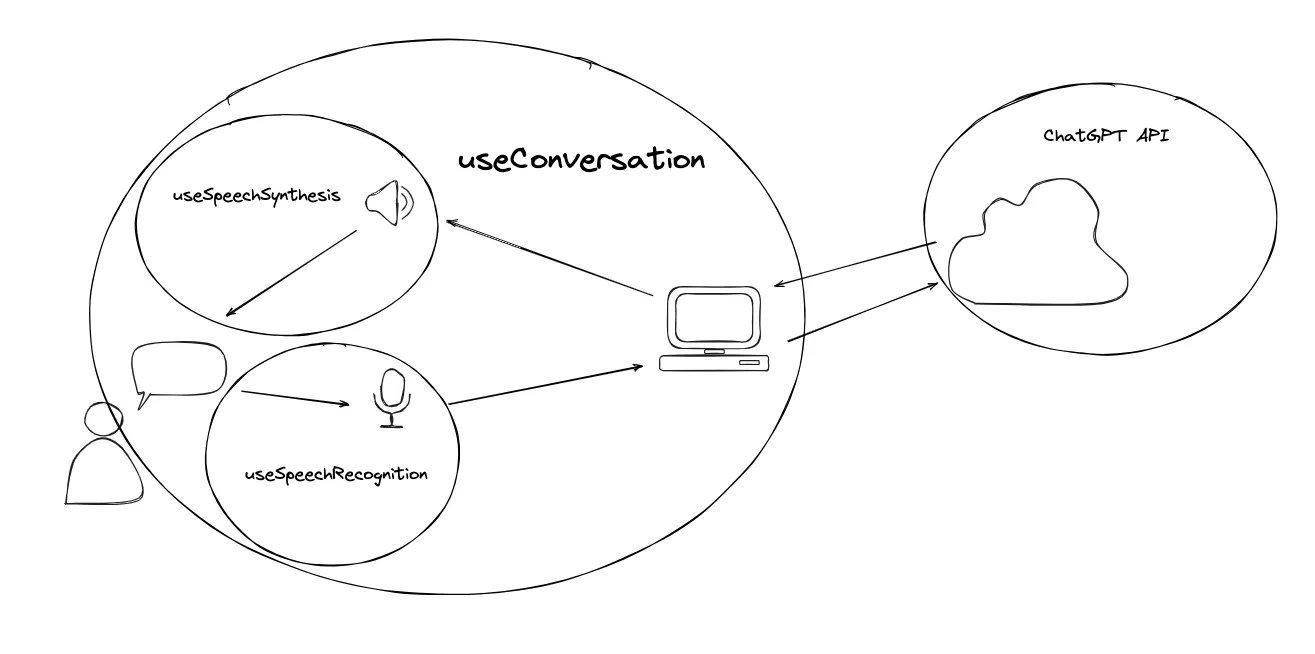
I’ve created a useSpeechRecognition hook that exposes utilities to:
- get the interim result to display in the UI
- check whether there is permission to use the microphone to show UI whether it is available or not
- request listening permission to the user
- know whether the Web API is currently listening the the user
- start listening to the user
- stop listening to the user
I’ve also created a useSpeechSynthesis hook that exposes a utility to speak to the user with a passed text string.
Finally, I’ve created a useConversation hook that:
Keeps track of the conversation state
"UNPERMITTED"- there is no permission yet to listen to the user’s microphone
"IDLING"- the application is currently not listening or responding
"LISTENING"- theuseSpeechRecognitionhook is listening the to the user’s microphone
"RESPONDING"- theuseSpeechSynthesishook is speaking to the user
"STOPPED"the user stopped the application
Uses the utilities exposed by the
useSpeechRecognitionanduseSpeechSynthesishooks to create a turn-based conversation
ChatGPT integration
So far, the application has yet to be hooked up to the ChatGPT API and is just responding with a fake answer. Let’s make the magic happen. All I need to do is create an API route in my Next.js application that receives two things in the form of a POST request:
messages- an array that consists of objects with a key ofrole- who is the message from? The"user"or the"assistant".content- the text string
aivaRole- what is the role of the AI to give it a bit of context on what it should behave like"assistant"- a general AI assistant that can virtually take up any role as long as the user instructs it to"tech-interviewer"- behave like a tech interviewer so a developer can practice an interview"scrum-master"- act like a scrum master and help a team with their scrum sessions"counselor"- be a counselor to the user providing them with a listening ear or advice
I added the aivaRole to give people using the demo an idea on what Aiva could be used for.
The user sends over a list of the whole conversation for context for the AI as it needs this for every request. I prepend this list with a bit of context for the AI so it knows it runs in a Voice UI, how it should behave/respond and finally the role the user set the AI to. This request then goes to the ChatGPT API, returns a response, returns that response to the front-end to finally be consumed by the useConversation hook.
React Three Fiber Visualisation
So yes, much like the OpenAI solution, you can now speak with the conversation. Besides mine feeling a bit more natural in the sense that it responds a lot quicker (~800ms), it still feels like you are talking with a ChatGPT API. We’ve stripped the need for traditional UI like inputs and text on the screen, but created a great new opportunity to give some personality to Aiva and simultaneously provide the needed feedback to the user (is it listening, responding etc.).
Why use this?
A few weeks back at the Frontmania Conference, Tim Beeren showed some amazing examples of Three.js using React Three Fiber. Another opportunity to try out something I haven’t worked with before! React Three Fiber basically allows a simpeler integration for using Three.js in a React.js application. This was good for me as I was not only using React.js to render the application, but also have the state of the conversation there which I wanted the visualisation to respond to.
How to use this?
I quickly realised that creating an awesome interactive visualisation would take quite a bit knowledge on subjects like shaders. Due to my incredibly short timeframe of two days to build the entire application, I took an existing visualisation and made it interact with the state of the conversation. I had control over two parameters:
speedthe speed of the movement of the blobintensitythe intensity of the spikes in the blob
I could then create a little hook to change these values based on the conversation state:
useEffect(() => {
switch (conversationState) {
case 'RESPONDING':
speed = 2
intensity = 0.75
break
case 'LISTENING':
speed = 1.25
intensity = 0.35
break
case 'STOPPED':
case 'IDLING':
speed = 0.8
intensity = 0.1
break
case 'UNPERMITTED':
default:
speed = 0.5
intensity = 0.05
break
}
}, [conversationState])
The end result
With all the parts connected, I now have an application that caters a turn-based conversation where the state of the conversation is visualised through an interactive data visualisation. All of that without the need of a single piece of text or required user interaction on the screen! To showcase how these conversation can go, I’ve recorded this short screencast:
What are some practical use cases?
In this article I already highlighted a few use cases for demo purposes. The easy answer is that it can cater all use cases. If I boil down my application to its simplest form I created a nice input-output system for a conversation. Whatever the user wants to use it for they can tell the AI and it will, if appropriate, follow. A few more examples (which I naturally asked ChatGPT for):
- Customer Support: ChatGPT can be used as a virtual customer support agent, handling common queries, providing information, and resolving issues.
- Sales Assistance: ChatGPT can act as a virtual sales assistant, engaging with potential customers, answering questions about products or services, and providing recommendations.
- Personal Assistant: ChatGPT can assist individuals in managing their schedules, setting reminders, making appointments, and helping with day-to-day tasks.
- Content Creation: ChatGPT can generate blog posts, social media captions, or marketing copy, helping businesses with their content creation needs.
- Language Translation: ChatGPT can facilitate real-time language translation, allowing users to communicate with individuals who speak different languages.
- Lead Generation: ChatGPT can engage website visitors, qualify leads, and collect contact information, enhancing lead generation efforts for businesses.
- Training and Education: ChatGPT can be utilized as a virtual tutor or trainer, providing personalized learning experiences, answering questions, and delivering educational content.
- Market Research: ChatGPT can conduct surveys, gather feedback, and analyze customer preferences, helping businesses gain insights for market research purposes.
- Virtual Event Host: ChatGPT can serve as a virtual event host, guiding attendees, answering questions, and providing information about the event agenda or sessions.
- Personal Entertainment: ChatGPT can engage users in entertaining conversations, tell jokes, share interesting facts, or even play interactive storytelling games for personal enjoyment. The sky(net) is the limit!
What are the takeaways?
ChatGPT, or AI in general, is being developer at an incredible pace. What we mustn’t forget is that we also need to take into account how the user interacts with AI. By creating a more natural conversation with the use of voice and sound we vastly improve the user experience in interacting with these products. By no means is a regular chat interface bad, it just is really good for quite some use cases. That doesn’t mean we shouldn’t explore other possibilities and create awesome new user experiences!
I feel like the match between AI and voice is great! As mentioned earlier, I’ve created an application that used the SpeechRecognition Web API over six years ago and never since! Even though I found it cool, I hadn’t find the actual use case for the technique up until creating this demo application. Sometimes combining older techniques and principles with new state-of-the art technology can lead to some magic.
Take my concept, think about some practical applications you might have (at your company) and try it out! Let’s make super cool products!